

Proč a nač?
Už po vás někdo chtěl abyste svůj web, který jste úspěšně naplnili články, přílohami, obrázky, videi, komentáři, sdílenými zdroji a kdovíjakým dalším úžasným obsahem, doplnil výkonným vyhledáváním? No jasně! A pokud jste se vašich klientů ptali, jak má takové vyhledávání vypadat, často vám bylo řečeno: „… mnó tak nějak jako má Google ne?“ Určitě jste pak úspěšně polkli nevrlou poznámku, že by potom měli uvažovat o navýšení finančních injekcí řádově o 1xxxx, pokud chtějí vyvinout Google Search. A ono je to snažší než se zdá, open source komunita má co nabídnout a za jiné finance!
Apache SOLR potřebuje jen Javu, prohlížeč a textový editor, nikoliv zapojení velkých investičních skupin a výběrové řízení na servery a podobně. Rozjedete to na starším notebooku s MS Windows, takže než začnete alokovat serverové kapacity nebo objednávat externí služby (i ty jsou zde přístupné jako cloudová služby s vlastním API), vyzkoušejte si to hned.
Instalace bez legrace
Postupujme vždy podle oficiální dokumentace SOLR. Pokud změníte čísla (8_7) v URL tak se dostanete k dalším, starším i k novějším verzím. A podobně to platí i v ostatních odkazech do dokumentace nebo i uvedených direktiv volající aktuální verzi SOLR. Brzy zjistíte že některé věci lze spouštět trochu jinak, možno využít Docker atd. Nyní ale, pokud máme na Windows administrátorská práva, tak je spousta věcí jednodušších, jednoduše stáhneme distribuci SOLR, rozbalíme ZIP např. do C:\solr\solr.
První krůčky pod MS Windows
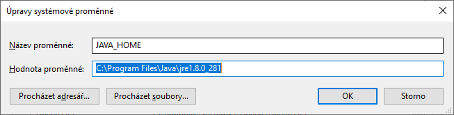
Pro spuštění SOLR potřebujeme Javu, pokud máme 64bitový systém, tak se bude hodit také 64bitová Java, instalace (ovšem pro starší verzi SOLR, ale to nevadí) a nastavení JAVA_PATH je popsaná zde.
V nastavení, resp. ovládacích panelech, dejte vyhledat Upravit proměnné systému, karta Upřesnit, tlačítko Proměnné prostředí … a řádek JAVA_HOME.
TIP: Pokud vám podobně jako mně Javu aktualizuje externí aplikace, která neumí tuto proměnnou aktualizovat, tak se při následujícím pokusu o start SOLR objeví hláška:
ERROR: java.exe not found in C:\Program Files\Java\jre…...
Please set JAVA_HOME to a valid JRE / JDK directory
Tak potom nezbude nic jiného než proměnnou ručně aktualizovat pomocí tlačítka Procházet adresář … Pro spuštění SOLR potřebujete trochu umět s příkazovou řádkou, přejděte do cílového adresáře s rozbalenou distribucí: cd C:\solr\solr, a poté
bin\solr.cmd start
TIP: zkuste zkratku Win+R a zadat “cmd” a jste v příkazovém řádku.
Nebo pro milovníky modré barvy: Win+X a vyberte Windows PowerShell (správce), i tak vám bude systém psát při pokusu o spuštění s vyšší přidělenou pamětí (zde 1 GB):
PS C:\solr\solr> bin\solr.cmd start -m 1g
"java version info is 1.8.0_281"
"Extracted major version is 1"
Java HotSpot(TM) 64-Bit Server VM warning: JVM cannot use large page memory
because it does not have enough privilege to lock pages in memory.
Waiting up to 30 to see Solr running on port 8983
Started Solr server on port 8983. Happy searching!
Což nám nevadí, zkoušíme si SOLR jen pro sebe a s doporučenými ukázkovými příklady nám postačí základní přidělená paměť. Důležité je až to poslední sdělení, SOLR se hlásí pod výchozím portem 8983 (lze v konfiguraci SOLRu změnit, zatím to nedělejte, bude možné kopírovat ukázkové URL přímo z dokumentace). V prohlížeči zadejte http://localhost:8983 a budete přesměrování na administrační konzoli SOLRu.
Když se nedaří
Když uděláte chybu, např. zkopírujete kolekci (collection, v názvosloví SOLR je to něco jako databáze) do záložní verze ve stejném adresáři, SOLR se pokusí načíst i tento adresář jako novou kolekci. Ale jelikož má v metadatech identický název, který musí mít každá kolace unikátní, vyskytne se problém už při startu SOLR:
ERROR: Solr at http://localhost:8983/solr did not come online within 30 seconds!
A v prohlížeči vidíte hlášku která vám nic moc nenapoví:
HTTP ERROR 404 javax.servlet.UnavailableException: Error processing the request.
CoreContainer is either not initialized or shutting down. …
Musíte nejdřív SOLR resp. všechny jeho instance zastavit
C:\solr\solr> bin\solr.cmd stop -all
najít v logu v čem je problém (c:\solr\solr\server\logs), problém odstranit a SOLR znovu nastartovat.
Instalace na Ubuntu
Postupujeme například podle dokumentace, pozor pracujeme jen s novější verzí 8.7.0.
cd /opt
wget https://archive.apache.org/dist/lucene/solr/8.7.0/solr-8.7.0.tgz
tar xzf solr-8.7.0.tgz solr-8.7.0/bin/install_solr_service.sh --strip-components=2
Pro instalaci využijeme skript, který nám SOLR nainstaluje a službu rovnou pustí:
./install_solr_service.sh solr-8.7.0.tgz
Služba běží, zkusme ji tedy zastavit:
sudo service solr stop
A znovu rozjet:
sudo service solr start
Zjistit o ní více možno takto:
sudo service solr status
Nezapomeňme službu zabezpečit (omezení přístupu k portu nebo náročnější autentizací). Pro hladký běh bude SOLR potřebovat adekvátní přidělení RAM, pokud máte operační paměti dostatek, nebojme se jít třeba na 1 GB:
v /etc/default/solr.in.sh zvednout SOLR_HEAP="1g"
Vytvoření první kolekce
Začněme:
sudo su - solr -c "/opt/solr/bin/solr create -c mycollation1"
Potřebujeme tedy sudo oprávnění tak, abychom mohli vytvořit pod uživatelem solr novou kolekci (create … -c mycollation1). Pokud bychom to udělali přímo pod rootem, SOLR by neměl ke kolekci potřebný přístup a trochu matoucí může být, že se to projeví až při využití SOLR API, kdy příkazy API končí nepříliš specifickou chybou 500. Také se doporučuji vyhnout zakládání kolekce z administrátorského rozhraní, fungovalo mi to jen tak, že se vytvořil prázdný adresář pro kolekci patřící uživateli solr, a bylo nutné manuálně nakopírovat set konfiguračních souborů z /opt/solr-.../server/...configsets/_default/ celý adresář /conf.
Kolekce dvojího typu
1. Data-driven schema (Výchozí ve verzi 7+):
sudo su - solr -c "/opt/solr/bin/solr create -c mycol1 -n data_driven_schema_configs"
Parametrem data_driven_schema_config to říkáme explicitně. Navíc v tzv. schemaless modu se schéma se tvoří podle a ze struktury indexovaných dat, tj. nové parametry se automaticky přidají do schématu a pomocí autodetekce se určí jejich datový typ. Jednoduché a pohodlné pro vývoj a první krůčky.
2. Managed-schema: Klasický přístup, vhodný pro produkční nasazení SOLR, schéma musíme přesně definovat v konfiguračním XML souboru a formát a struktura indexovaných dat musí odpovídat, pokud ne, SOLR hlásí problém. Pokud chceme přejít na managed-schema, provedeme to v nastavení SOLR podle dokumentace:
Switching from Managed Schema to Manually Edited schema.xml
Jak na to?
- přejmenujeme soubor se schématem na schema.xml
- přidáme direktivu
- upravíme default="${update.autoCreateFields:false}"
Vše je podrobně popsáno v dokumentaci.



