
Poptávka o otevřených datech v průběhu pandemie rostla podobně jako hodnota bitcoinu v prvním čtvrtletí roku 2021. Požadavky na zveřejňování se během posledního roku točily především kolem dat o „covidu“, jelikož celé Česko v jistou chvíli sledovalo každodenní přírůstky pozitivit. Mnoho subjektů volá po zpřístupňování dalších a dalších datasetů a my se snažíme na tyto požadavky reagovat a data „otevírat“. Že to ale není jen tak, o tom mi povyprávěl vývojář z našeho týmu a hlavní tvůrce otevřených dat, Petr Panoška.
Co to znamená, že jsou data otevřená?
Otevřená data jsou v jednoduchosti data, která zveřejňují určité informace, a která splňují následující podmínky:
- jsou dostupná – jsou k dispozici na internetu,
- jsou svobodná – je pro ně stanovena otevřená licence,
- jsou strojově čitelná – jsou publikována ve formátu, který je strojově zpracovatelný.
Definice de iure: informace zveřejňované způsobem umožňujícím dálkový přístup v otevřeném a strojově čitelném formátu, jejichž způsob ani účel následného využití není omezen a které jsou evidovány v národním katalogu otevřených dat.
/// Jak mohou otevřená data vypadat?
To můžeme ukázat na tzv. 5hvězdičkovém modelu otevřených dat od Tima Berners-Leeho [1]. Jak už model napovídá, úroveň „kvality“ otevřených dat je hodnocena právě pomocí hvězdiček, přičemž platí obrácený systém jako ve škole: čím více hvězdiček, tím lépe. Větší počet hvězdiček indikuje větší nároky na podobu dat, viz Obrázek 1.
![Obrázek 1. 5hvězdičkový model otevřených dat [1]](https://webstudio.team/admin/media/cache/resolve/blog_photo/images/5-hvezdickovy-model-otevrena-data.jpg)
- 1* = data, která jsou pod otevřenou licencí (např. to mohou být i data v tabulce, která je ale uložená formou obrázku v JPEG)
- 2* = data s otevřenou licencí a navíc strukturovaná (čitelná, RE = readibility, například tabulka s daty ve formátu XLSX)
- 3* = data s otevřenou licencí, čitelná a navíc v otevřeném formátu (což je například formát CSV)
- 4* = data, která oproti předchozí úrovni mají navíc URI (pro jednotlivé entity v datech existují unikátní URI adresy, data lze díky tomu kombinovat, odkazovat se na jiné datasety), uchováváno jako RDF.
- 5* = nejvyšší úroveň, data jsou tzv. linked neboli propojená, lze je mezi sebou linkovat, dát jim kontext
Jak vypadá celý postup přípravy otevřeného datasetu?
Když někdo přijde s požadavkem na novou otevřenou datovou sadu, dal by se postup shrnout do 5 kroků:
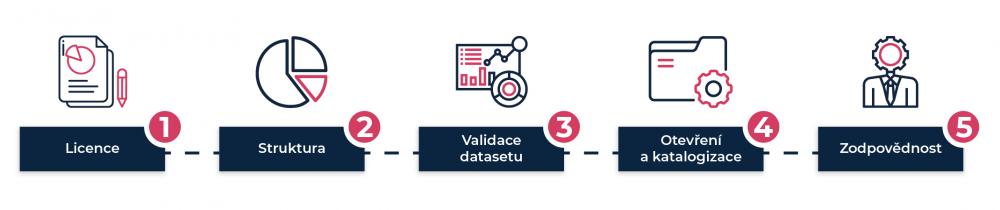
/// 1. krok: licence
Potřebujeme stanovit, zda data můžeme publikovat. Klademe si otázky: Neporušíme autorské zákony? Neporušíme ochranu osobních údajů? Jsou data anonymizovaná? To jsou jedny ze základních otázek před tím, než se datům udělí otevřená licence.
/// 2. krok: struktura
Musíme se pořádně zamyslet nad tím, jak budou data vypadat. Jaké budou mít atributy (sloupce), jaké budou datové typy. Při těchto debatách rovnou nadefinujeme schéma datasetu a popíšeme každý jeho atribut. To ale není vše. Stanovujeme i validační/filtrační pravidla, aby se do dat nedostal nepozorovaně nějaký nepořádek.
/// 3. krok: validace datasetu
Výsledek našeho snažení je nutné zvalidovat oproti jeho navrženému schématu. Na tu využíváme nástroj od vývojářů, kteří mají na starost Národní katalog otevřených dat – csvw validator. Co je výsledkem? V lepším případě zelený pruh s hláškou „Je to OK“, v tom horším pak seznam chyb. Je to mimochodem velmi užitečné a my máme jistotu, že publikujeme validní a konzistentní data.
/// 4. krok: otevření a katalogizace
V tomto kroku je to hodně technické, data proháníme přes PHP aplikaci, leze to z Postgre, pak se to vyplivne do CSV… výsledná data se musí vystavit na unikátní URL adresu no a pak se dataset musí katalogizovat. To je možné udělat dvěma způsoby:
- každý dataset poslat a zaregistrovat do národního katalogu otevřených dat napřímo, nebo
- když máte dost datasetů, jako my, můžete mít vlastní katalog vlastní katalog. Do něj posíláme z Onemocnění aktuálně metadata o umístění a vlastnostech datasetu. Vytvoří se záznam v katalogu, čímž se vygeneruje ID, a pro katalogizační záznam se nadefinují metadata (URL, odkaz na podmínky užití, schéma zdroje, od kdy apod.). Naši aplikaci pak napíchneme na API tohoto lokálního katalogu, takže metadata se pak aktualizují strojově.
Národní katalog pak sbírá informace z tohoto našeho lokálního katalogu, a tak jsou všechny datasety na 1 místě.
/// 5. krok: zodpovědnost
S každým datasetem přichází zodpovědnost, protože nechceme zklamat naše uživatele. Musíme tedy za data ručit, musíme zajistit dostupnost datových sad a katalogu a přemýšlet i o jejich budoucnosti. Publikací dat naše práce rozhodně nekončí.
Datasety publikujeme, jak už bylo zmíněno, v tom zlatém středu 5hvězdičkového modelu. Rozhodně ale chceme otevírání posunout dál, respektive výše. To pak mluvíme o propojování dat, výběru slovníků, RDF… o tom ale někdy jindy, nebo až budeme mít první takovou vypublikovanou sadu :).
Jak dlouho trvá vytvoření sady od otevřené licence po katalogizační záznam?
To je těžké takhle hodnotit, různí se to totiž podle charakteru dat. Když by se jednalo o nějakou menší, jednoduchou datovou sadu, kde se nezdržíme diskusemi o právních aspektech či porušení GDPR, tak je celý proces otázka pár hodin.
Horší jsou situace, kdy mám data z různých zdrojů. To jsou reálné případy, kdy nemám pouze jednu databázi, některá data sbíráme odjinud, je potřeba se napíchnout na jiné API… záleží na původu dat. Překážky se pak najdou i tam, kde by je mnozí nečekali, a netroufnu si odhadnout přesný čas tvorby takového datasetu.
Jak je to s automatizací?
Automatizaci lze popsat na příkladu ze srpna 2021, kdy naše datasety prochází každý den dvěma updaty. První se provádí už s prvním kohoutím kokrháním – přesně ve 4 hodiny ráno, kdy se pouští aktualizace očkovaných. Další se pak pouští v 7:40, kdy se každý den nanovo plní databáze ze zdrojové tabulky. Po tomto přelití dat se vytvoří CSV a JSON datasety a automaticky se zaktualizuje i lokální katalog. Všechno máme řešené v naší aplikaci.
V minulosti docházelo k různým změnám a posunům, po roce zkušeností byly časy aktualizací ustáleny na těchto časech. Už tak fungujeme nějaký ten pátek, dokážeme pak i lépe reagovat na případné chyby, neúplná data, nedojeté nebo nespuštěné aktualizace…
Na závěr – co nedělat?
Trochu se do budoucna bojím o publikování obrovských JSON souborů, o kterých byla řeč výše. Zpomaluje to celý proces a zbytečně zabírá diskový prostor. Chystaná nová verze API zmíněná výše by měla tyto trable vyřešit.
Za zmínku určitě stojí i úpravy datasetů. Když se například přidává nějaký atribut do datové sady, určitě jej přidáváme vždy na konec pro případ, že by někdo indexoval podle pořadí sloupců.
Taky jsme v minulosti neměli sjednocené názvy některých sloupců, někde jsme měli „okres_kod“, jinde „kod_okres“. Jsou to sice drobnosti, ale tyto atributy jsme sjednotili a při nových datasetech pojmenováváme s ohledem na ty starší.
Aktuální informace a novinky o zdravotnických datech
V souvislosti s otevřenými daty určitě stojí za zmínku také náš projekt data.nzis.cz, který na jednom místě informuje o veškerých aktualitách či událostech ze světa zdravotnických dat.
Použité zdroje
[1] 5hvězdičkový model otevřených dat



